Telecom Customer Churn Prediction
Supervised Learning Capstone Project
In this notebook, telecom customer data was read in to determine whether customer churn can be predicted. As shown below, both random forest and logistic regression modelling yielded similar results with accuracies of ~80% on the test set data.
One key insight from the data was also that customers with month-to-month contracts are more likely to churn than other customers. In this subset of customers, the shorter tenure a customer has the higher they are to churn.
Note that the code for this project can also be found at the following Github repository: here
Please note that this project was done as part of the 2021 Python for Machine Learning & Data Science Masterclass on Udemy
Summary of Results
Based on the models run, customer churn can be predicted with ~79% accuracy via a random forest or logistic regression model.
From our EDA, it appears that contract type in particular can be important in predicting churn. Specifically, customers who are on a month to month plan are more likely to churn than other contract types, and especially those who have had plans for 0-12 months.
In the future, a company could use models to predict whether a customer is likely to churn, enact an intervention strategy to prevent churn, and optimize business strategy to proactively minimize churn.
Import required packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
EDA
Load Data
First I load in the relevant data.
df = pd.read_csv('./DATA/Telco-Customer-Churn.csv')
Data Structure And Information Exploration
After loading in the data I look at the data structure, check for null values to determine whether imputation/deletion is required, and view column descriptive statistics to get a high-level summary of the quantitative data.
df.head()
Data Structure And Information Exploration
After loading in the data I look at the data structure, check for null values to determine whether imputation/deletion is required, and view column descriptive statistics to get a high-level summary of the quantitative data.
df.head()
| customerID | gender | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | … | MonthlyCharges | TotalCharges | Churn |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Female | No | 1 | No | No phone service | DSL | No | … | 29.85 | 29.85 | No |
| 1 | Male | No | 34 | Yes | No DSL | Yes | Yes | … | 56.95 | 1889.50 | No |
| 2 | Male | No | 2 | Yes | No DSL | Yes | Yes | … | 53.85 | 108.15 | Yes |
| 3 | Male | No | 45 | No | No phone service | DSL | Yes | … | 42.30 | 1840.75 | No |
| 4 | Female | No | 2 | Yes | No Fiber optic | No | Yes | … | 70.70 | 151.65 | Yes |
df.info()
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | customerID | 7032 non-null | object |
| 1 | gender | 7032 non-null | object |
| 2 | SeniorCitizen | 7032 non-null | int64 |
| 3 | Partner | 7032 non-null | object |
| 4 | Dependents | 7032 non-null | object |
| 5 | tenure | 7032 non-null | int64 |
| 6 | PhoneService | 7032 non-null | object |
| 7 | MultipleLines | 7032 non-null | object |
| 8 | InternetService | 7032 non-null | object |
| 9 | OnlineSecurity | 7032 non-null | object |
| 10 | OnlineBackup | 7032 non-null | object |
| 11 | DeviceProtection | 7032 non-null | object |
| 12 | TechSupport | 7032 non-null | object |
| 13 | StreamingTV | 7032 non-null | object |
| 14 | StreamingMovies | 7032 non-null | object |
| 15 | Contract | 7032 non-null | object |
| 16 | PaperlessBilling | 7032 non-null | object |
| 17 | PaymentMethod | 7032 non-null | object |
| 18 | MonthlyCharges | 7032 non-null | float64 |
| 19 | TotalCharges | 7032 non-null | float64 |
| 20 | Churn | 7032 non-null | object |
Based on the above, I see that there are no null values in the data and thus no imputation/deletion is needed.
df.describe()
| SeniorCitizen | tenure | MonthlyCharges | TotalCharges | |
|---|---|---|---|---|
| count | 7032.000000 | 7032.000000 | 7032.000000 | 7032.000000 |
| mean | 0.162400 | 32.421786 | 64.798208 | 2283.300441 |
| std | 0.368844 | 24.545260 | 30.085974 | 2266.771362 |
| min | 0.000000 | 1.000000 | 18.250000 | 18.800000 |
| 25% | 0.000000 | 9.000000 | 35.587500 | 401.450000 |
| 50% | 0.000000 | 29.000000 | 70.350000 | 1397.475000 |
| 75% | 0.000000 | 55.000000 | 89.862500 | 3794.737500 |
| max | 1.000000 | 72.000000 | 118.750000 | 8684.800000 |
Visual Exploration
Now that I have a better sense of data structure and overall statistics, I can explore the data visually.
First I will drop the customerID column since this is unique for each row and not useful for classification or visualization.
df.drop('customerID', axis=1, inplace=True)
Next I will generate a countplot of customer churn to see whether the target data is imbalanced.
plt.figure(figsize=(15,5))
sns.countplot(data=df, x='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.ylabel("Count")
plt.xlabel("Churn Status")
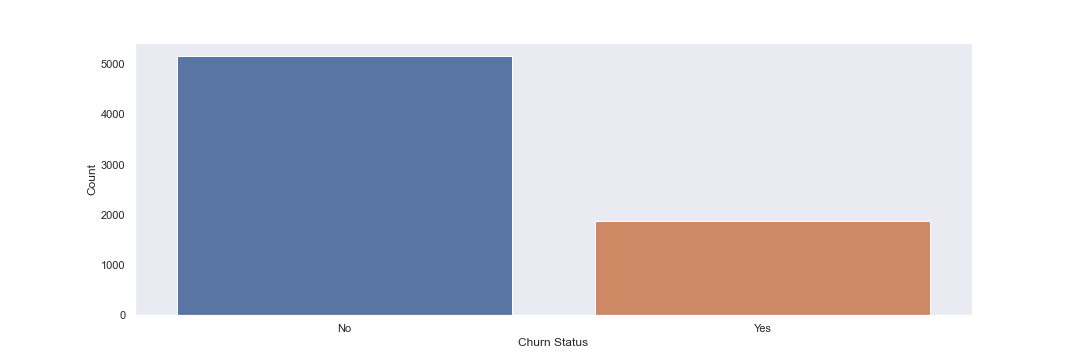
Based on the above plot, I see that the data is imbalanced, with ~2.5x No’s than Yes’
Next I will plot customer churn vs TotalCharges via a violin plot. This can help me understand the distribution of the target variable and if there are any trends or target areas for further analysis.
plt.figure(figsize=(15,5))
sns.violinplot(data=df,y='TotalCharges',x='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Churn Status")
plt.ylabel("Total Charges ($)")
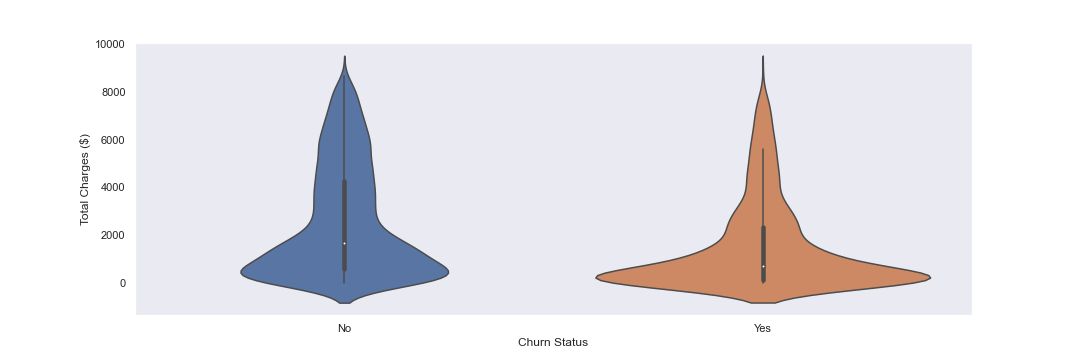
In the above, I see that there is a jump in TotalChares at ~$1000.
Next, I will plot contract types vs TotalCharges, with a hue of Churn, in boxplots. This can help me determine whether contract type appears to have an influence on churn.
plt.figure(figsize=(15,5))
sns.boxplot(data=df,x='Contract',y='TotalCharges',hue='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Contract Type")
plt.ylabel("Total Charges ($)")
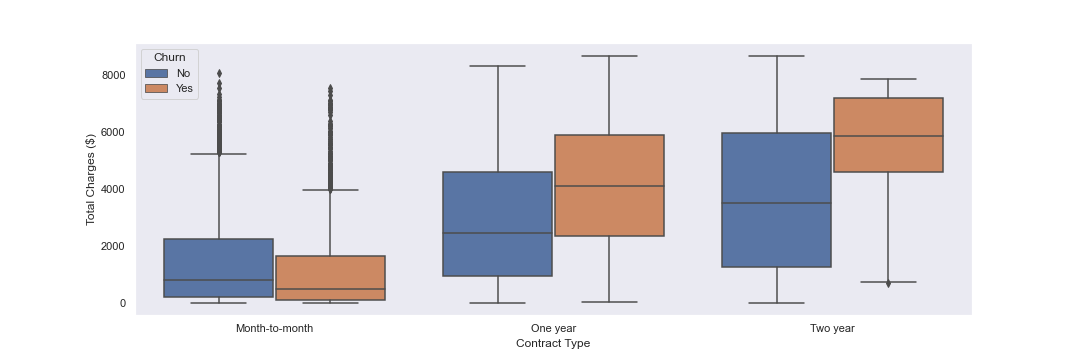
Finally, I will create a correlation matrix for features with the churn variable
#use df.head as a refresher of the df structure and columns
df.head()
| customerID | gender | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | … | MonthlyCharges | TotalCharges | Churn |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Female | No | 1 | No | No phone service | DSL | No | … | 29.85 | 29.85 | No |
| 1 | Male | No | 34 | Yes | No DSL | Yes | Yes | … | 56.95 | 1889.50 | No |
| 2 | Male | No | 2 | Yes | No DSL | Yes | Yes | … | 53.85 | 108.15 | Yes |
| 3 | Male | No | 45 | No | No phone service | DSL | Yes | … | 42.30 | 1840.75 | No |
| 4 | Female | No | 2 | Yes | No Fiber optic | No | Yes | … | 70.70 | 151.65 | Yes |
corr_df = pd.get_dummies(df[['gender', 'SeniorCitizen', 'Partner', 'Dependents','PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport','StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod','Churn']]).corr()
corr_df['Churn_Yes'].sort_values().iloc[1:-1]
|Column|Correlation| |—|—| |Contract_Two year |-0.301552| |StreamingMovies_No internet service |-0.227578| |StreamingTV_No internet service |-0.227578| |TechSupport_No internet service |-0.227578| |DeviceProtection_No internet service |-0.227578| |OnlineBackup_No internet service |-0.227578| |OnlineSecurity_No internet service |-0.227578| |InternetService_No |-0.227578| |PaperlessBilling_No |-0.191454| |Contract_One year |-0.178225| |OnlineSecurity_Yes |-0.171270| |TechSupport_Yes |-0.164716| |…|…| |SeniorCitizen | 0.150541| |Dependents_No | 0.163128| |PaperlessBilling_Yes | 0.191454| |DeviceProtection_No | 0.252056| |OnlineBackup_No | 0.267595| |PaymentMethod_Electronic check | 0.301455| |InternetService_Fiber optic | 0.307463| |TechSupport_No | 0.336877| |OnlineSecurity_No | 0.342235| |Contract_Month-to-month | 0.404565|
Plot the correlation of features with churn
plt.figure(figsize=(15,5))
plt.xticks(rotation=90)
sns.barplot(x=corr_df['Churn_Yes'].sort_values().iloc[1:-1].index, y=corr_df['Churn_Yes'].sort_values().iloc[1:-1].values)
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Variables")
plt.ylabel("Correlation with Churn")
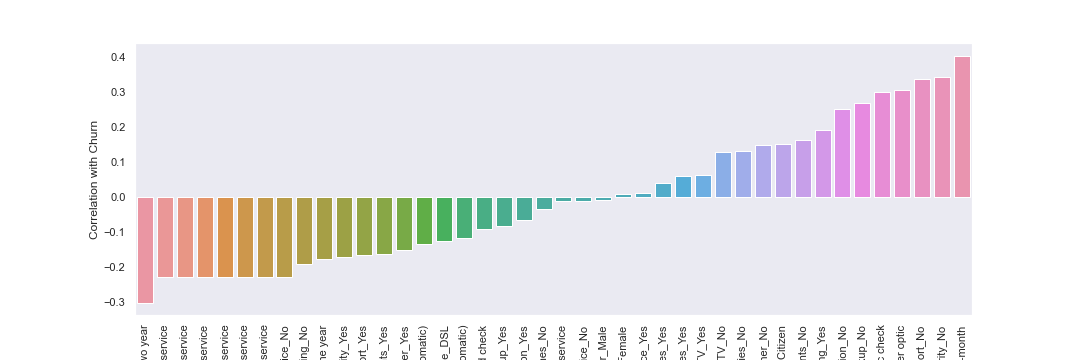
Based on the above, contract month-to-month appears to have the highest correlation to churn. Let’s conduct more analysis with the contract features below.
Churn Analysis
Now that I have explored the data, I can begin to analyze churn in the dataset.
Tenure and Contract Type Anaysis
First I will analyze tenure and contract type as they relate to churn, since churn is correlated highly with monthly contracts and we want customers to have higher tenure with the company.
To start, I will confirm the different contract types.
df['Contract'].unique()
# ['Month-to-month', 'One year', 'Two year']
Next I will create a historgram displaying the distribution of the tenure column, which is the amount of time a customer has been / was a customer.
plt.figure(figsize=(15,5))
sns.histplot(data=df,x='tenure',bins=25)
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Tenure Bins (years)")
plt.ylabel("Count")
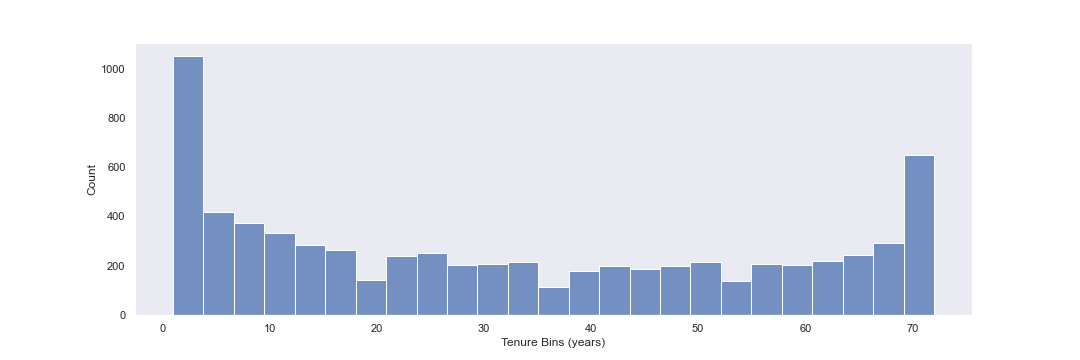
There is a wide distribution of tenure in this dataset, with several apparent spikes around 3 months and 70 months.
Next, I will plot tenure partitioned by each contract type and customer churn target values.
plt.figure(figsize=(15,5),dpi=200)
sns.displot(data=df,x='tenure',bins=70,col='Contract',row='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
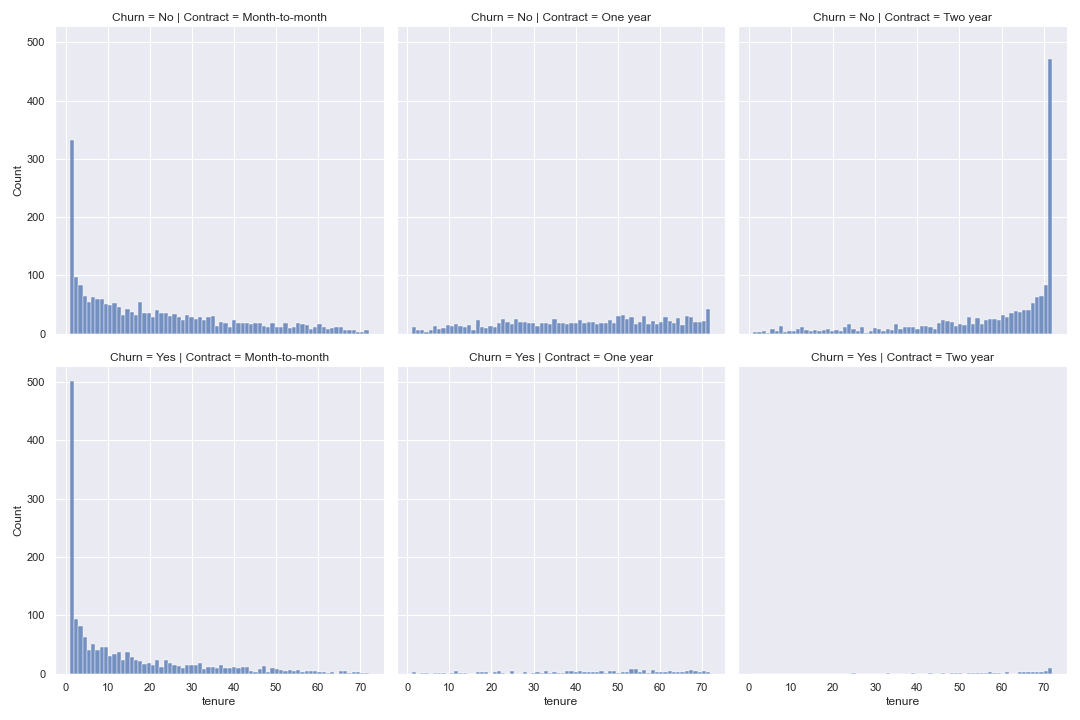
Based on the above, it would appear that customers with month-to-month contracts tend to have high churn early and then relatively small churn numbers thereafter.
For one and two year contracts, there does not appear to be a spike or pattern indicating how long it take these customers to churn on average.
Monthly Charge Analysis
In addition to tenure, another characteristic at our disposal is the monthly charge figure. To see whether monthly charges have an impact on churn, I make a scatter plot of Total Charges vs Monthly Charges, and color hue by Churn.
plt.figure(figsize=(15,5),dpi=200)
sns.scatterplot(data=df, x='MonthlyCharges', y='TotalCharges', hue='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Monthly Charges ($)")
plt.ylabel("Total Charges ($)")
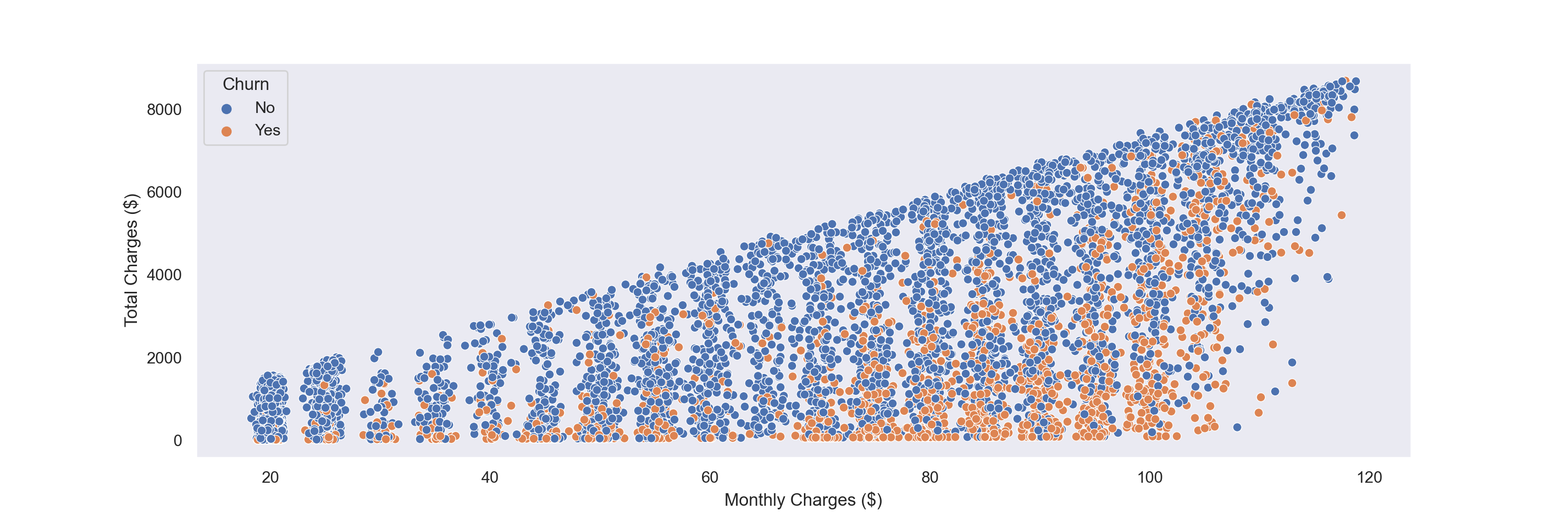
As seen above, customers are shown to churn at many different MonthlyCharges values. However, there does appear to be more churn as MonthlyCharges get higher.
Creating Cohorts based on Tenure
Next, I will treat each tenure group as a cohort, and calculate the Churn rate per cohort.
no_churn = df.groupby(['Churn', 'tenure']).count().transpose()['No']
yes_churn = df.groupby(['Churn', 'tenure']).count().transpose()['Yes']
churn_rate = 100*yes_churn / (no_churn+yes_churn)
churn_rate.transpose()['gender']
| # | tenure |
|---|---|
| 1 | 61.990212 |
| 2 | 51.680672 |
| 3 | 47.000000 |
| 4 | 47.159091 |
| 5 | 48.120301 |
| … | … |
| 68 | 9.000000 |
| 69 | 8.421053 |
| 70 | 9.243697 |
| 71 | 3.529412 |
| 72 | 1.657459 |
With the above data created, I will now plot churn rate per month.
plt.figure(figsize=(15,5))
churn_rate.iloc[0].plot()
plt.ylabel('Churn Rate')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Tenure (years)")
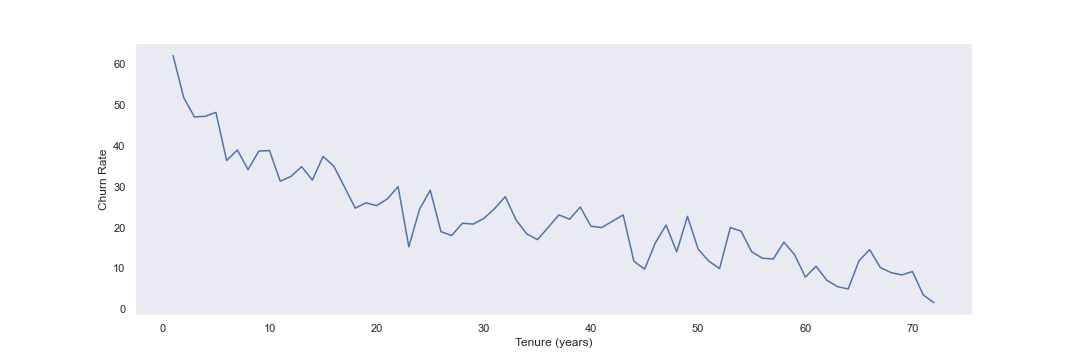
As seen above, it appears that the generally, higher tenure correlates with lower churn rates.
Based on the tenure column values above, I can create a new column called Tenure Cohort that create 4 categories:
- 0-12 months
- 12-24 months
- 24-48 months
- over 48 months
def tenure_cohort(tenure):
if tenure<13:
return '0-12 months'
elif tenure<25:
return '12-24 months'
elif tenure<49:
return '24-48 months'
return 'over 48 months'
df['tenure_cohort'] = df['tenure'].apply(tenure_cohort)
With the new cohort column created, I can now create a scatter plot of total charges vs monthly costs, colored by tenure cohort
plt.figure(figsize=(10,5),dpi=200)
sns.scatterplot(data=df, x='MonthlyCharges', y='TotalCharges', hue='tenure_cohort', alpha=0.5)
sns.set(rc={'figure.facecolor':'white'})
plt.grid(False)
plt.xlabel("Monthly Charges ($)")
plt.ylabel("Monthly Charges ($)")
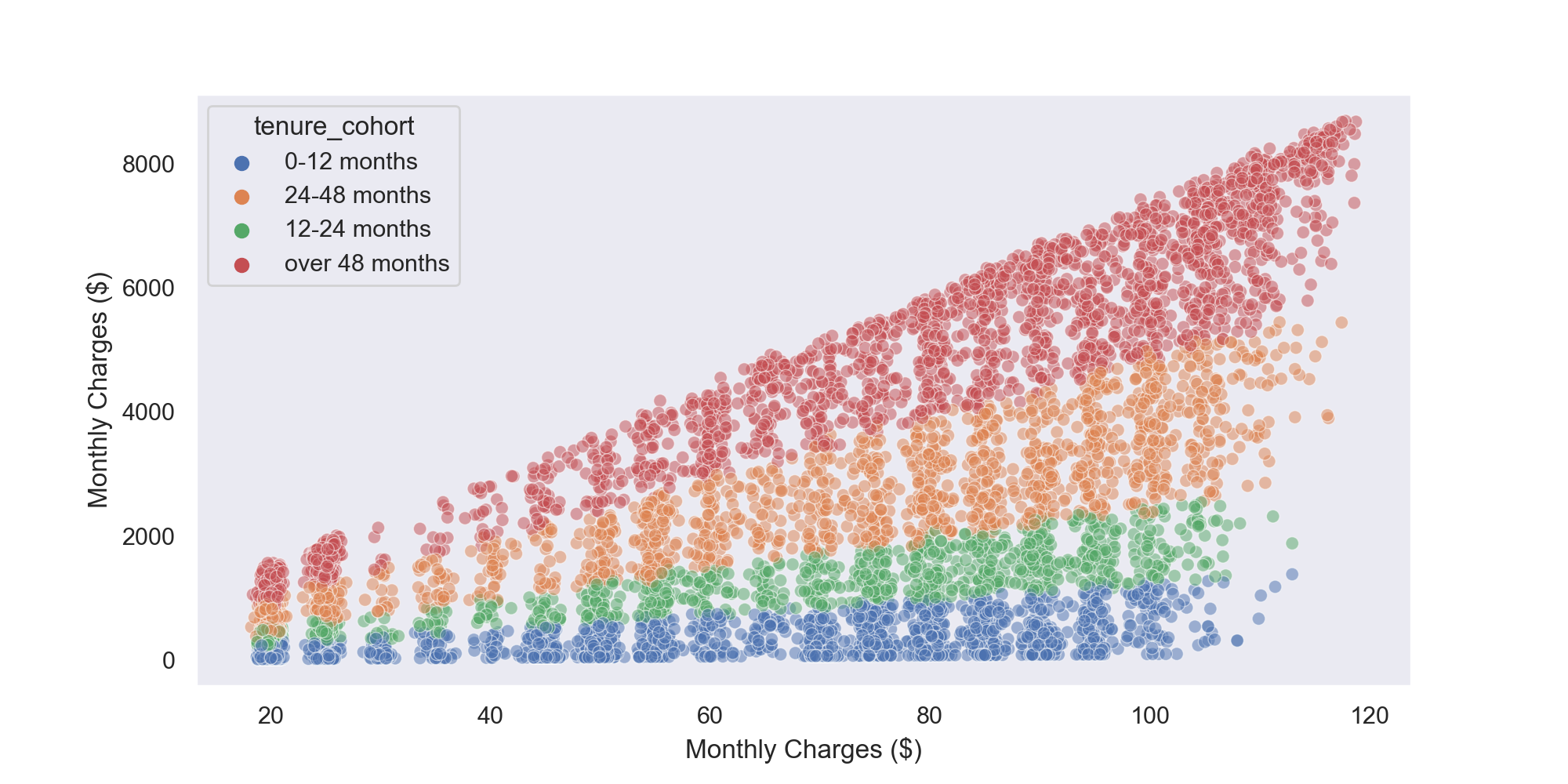
The chart above appears to show that customers with higher tenure tend to have higher TotalCharges and MonthlyCharges. The TotalCharges trend makes sense, since older customers have had more pay cycles and thus have higher cumulative charges on their accounts.
There could be several explanations for why newer customers tend to have lower rates, including that they may get low promotional rates to join the company and they haven’t had as much time to have their monthly rates increased.
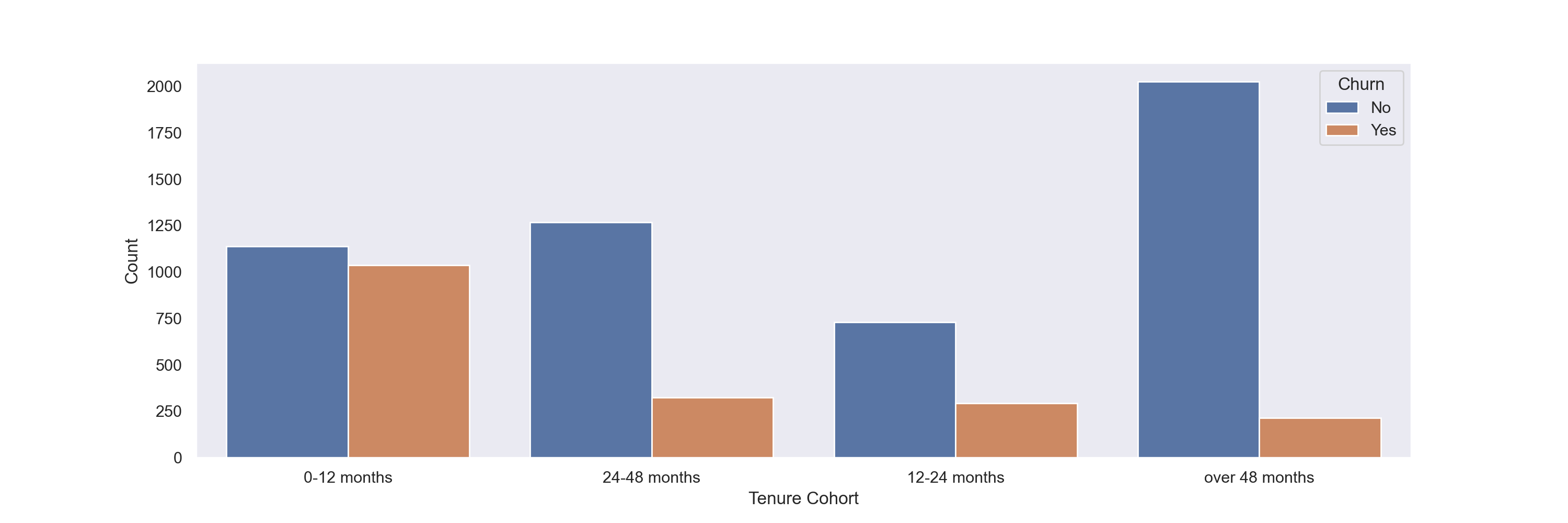
Since it appears that the cohorts are in clear ‘bands’ above, I will create a count plot showing the churn count per cohort to better quantify this trend.
plt.figure(figsize=(15,5),dpi=200)
sns.countplot(data=df,x='tenure_cohort',hue='Churn')
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
plt.xlabel("Tenure Cohort")
plt.ylabel("Count")
plt.figure(figsize=(15,5),dpi=200)
g = sns.catplot(x="tenure_cohort", hue="Churn", col="Contract",data=df, kind="count")
sns.set(rc={'figure.facecolor':'white'})
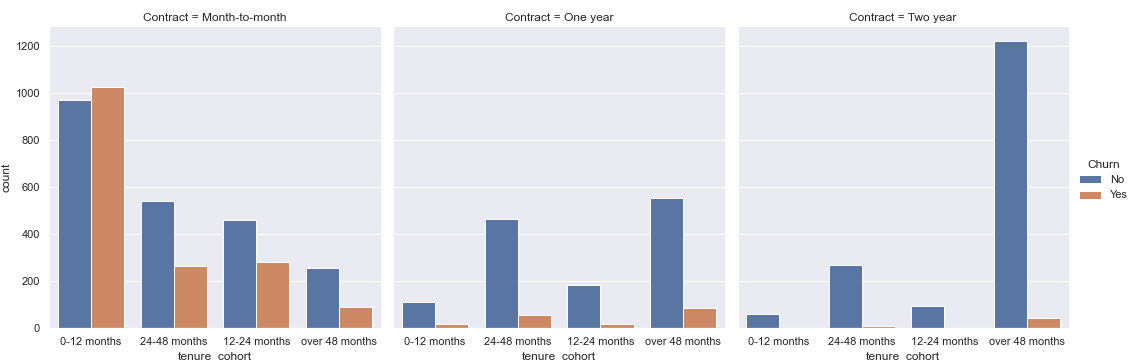
From the above two plots, I see that churn numbers are highest within the first 12 months of tenure.
Further, much of the churn both in the first 12 months and overall occurs in month-to-month contracts.
Predicting Customer Churn
After exploring and analyzing the provided data, I can now create a predictive model to help the telecom company identify likelihood of churn and perform an intervention / program to provent churn.
Prepare the data for Modelling
First I split the data into input and target feature sets
X=df.drop('Churn', axis=1)
y=df['Churn']
Next I get dummies for categorical values so that they can be included in machine learning model processes.
X = pd.get_dummies(X,drop_first=True)
I perform a train test split of the data so that data can be used to both train a model and validate it’s effectiveness.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Some models, like random forests, do not require feature scaling. Scaling will be performed for models that require it in the below.
Random Forest Modelling
Import accuracy metrics and model
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, plot_confusion_matrix,classification_report
Perform grid search to find optimal params
rf_model = RandomForestClassifier()
param_grid = {'n_estimators':[50,100], 'max_depth': [2,4,6,8,10]}
grid = GridSearchCV(rf_model,param_grid)
grid.fit(X_train, y_train)
grid.best_params_
# max_depth: 8, estimators: 100
Use the best parameters to create a random forest model and assess its accuracy/metrics.
plt.figure(figsize=(15,5))
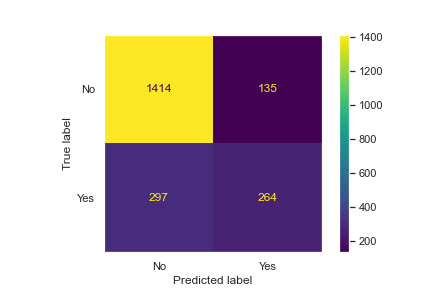
plot_confusion_matrix(grid,X_test,y_test)
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
accuracy_score(y_test,preds)
accuracy: 0.7933649289099526
print(classification_report(y_test,preds))
| . | precision | recall | f1-score | support |
|---|---|---|---|---|
| No | 0.82 | 0.91 | 0.87 | 1549 |
| Yes | 0.66 | 0.46 | 0.54 | 561 |
| accuracy | … | … | 0.79 | 2110 |
| macro avg | 0.74 | 0.69 | 0.70 | 2110 |
| weighted avg | 0.78 | 0.79 | 0.78 | 2110 |
From the above, we see that a random forest model is ~79% accurate overall.
Logistic Regression
Now I will try implementing a logistic regression model on this data, to see whether we can get better results than the above.
The data is already split, however we need to scale our data so the model can run optimally, since regressors are more sensitive to data being placed at different scales.
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_X_train = scaler.fit_transform(X_train)
scaled_X_test = scaler.transform(X_test)
log_model = LogisticRegression()
penalty = ['l1','l2','elastic_net']
l1_ratio = np.linspace(0,10,20)
C = np.logspace(0,10,20)
param_grid = {'l1_ratio':l1_ratio, 'penalty':penalty, 'C':C}
grid_model = GridSearchCV(log_model, param_grid=param_grid)
grid_model.fit(scaled_X_train,y_train)
grid_model.best_params_
# {'C': 11.28837891684689, 'l1_ratio': 0.0, 'penalty': 'l2'}
y_pred = grid_model.predict(scaled_X_test)
accuracy_score(y_test,y_pred)
# accuracy: 0.7919431279620853
plt.figure(figsize=(15,5))
plot_confusion_matrix(grid_model,scaled_X_test,y_test)
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
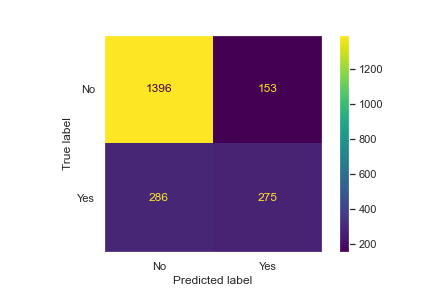
print(classification_report(y_test,y_pred))
| . | precision | recall | f1-score | support |
|---|---|---|---|---|
| No | 0.83 | 0.90 | 0.86 | 1549 |
| Yes | 0.64 | 0.49 | 0.56 | 561 |
| accuracy | … | … | 0.79 | 2110 |
| macro avg | 0.74 | 0.70 | 0.71 | 2110 |
| weighted avg | 0.78 | 0.79 | 0.78 | 2110 |
I see very similar accuracy scores and confusion matrix results for both random forest and logistic regression models.
KNN
Finally, I conduct a KNN model.
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
param_grid_knn = {'n_neighbors':[2,5,7,10]}
grid_knn = GridSearchCV(knn_clf,param_grid_knn)
grid_knn.fit(scaled_X_train,y_train)
grid_knn.best_params_
# {'n_neighbors': 7}
knn_preds = grid_knn.predict(scaled_X_test)
plt.figure(figsize=(15,5))
plot_confusion_matrix(grid_knn,scaled_X_test,y_test)
plt.grid(False)
sns.set(rc={'figure.facecolor':'white'})
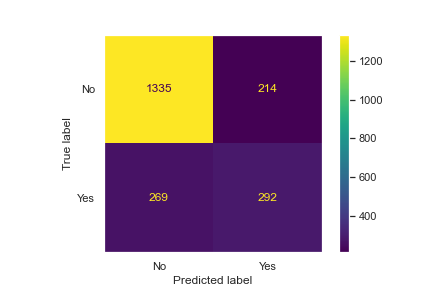
print(classification_report(y_test,knn_preds))
| . | precision | recall | f1-score | support |
|---|---|---|---|---|
| No | 0.83 | 0.86 | 0.85 | 1549 |
| Yes | 0.58 | 0.52 | 0.55 | 561 |
| accuracy | … | … | 0.77 | 2110 |
| macro avg | 0.70 | 0.69 | 0.70 | 2110 |
| weighted avg | 0.76 | 0.77 | 0.77 | 2110 |
The KNN model performs slightly worse than our other two models.
Results
Summary of Model Performance
| Model | Weighted Avg Precision | Weighted Avg Recall | Weighted Avg F1-score | Accuracy |
|---|---|---|---|---|
| Random Forest | 0.78 | 0.79 | 0.78 | 0.79 |
| Logistic Regression | 0.78 | 0.79 | 0.78 | 0.79 |
| KNN | 0.76 | 0.77 | 0.77 | 0.77 |
Conclusion
Based on the models run, customer churn can be predicted with ~79% accuracy via a random forest or logistic regression model.
From our EDA, it appears that contract type in particular can be important in predicting churn. Specifically, customers who are on a month to month plan are more likely to churn than other contract types, and especially those who have had plans for 0-12 months.
Next Steps
In the future, a company could use one of the above models to predict whether a customer is likely to churn. With this information, the company could then decide how (and whether) to intervene and prevent the customer from cancelling service.
The company could also evaluate the factors most correlated with churn and determine whether they can alter their strategy and reduce churn from particular components of the business.